Originally published on Forbes’ website by Ed Stacey, Managing Partner.
‘Human in the Loop’ Learning (HITL), describes a setup whereby a learning machine or computer system can incorporate selected human inputs or labels into its inferences or learning process, and thereby create a virtuous cycle or ‘loop’ in which the machine constantly learns to improve its capabilities. HITL is becoming an increasingly used, yet still rather overlooked method in advancing today’s AI systems – perhaps not helped by the popular dichotomy between tasks being either fully manual or fully automated. Yet, systems designers are increasingly realising that full automation shouldn’t necessarily be the goal: that sometimes the best results are achieved through humans and machines cooperating – with humans (at least those with the right kinds of knowledge) interacting with the (right kinds of) AI.
The ‘right kind of knowledge’, of course, depends very much on the task at hand. For instance, if the task is to understand unstructured text in electronic health records, perhaps in order to diagnose patients for particular diseases (as is being pioneered by startup Pangaea), then it is rather important that the HITL humans involved are highly qualified medical practitioners. Whereas if the task is to label objects in a visual scene – say for training an autonomous vehicle – then most humans would be qualified to do the job and so a crowd platform such as Amazon’s Mechanical Turk might be suitable.
In both cases however, it’s almost always the case that human feedback is relatively costly compared to the machine resources, so a key goal of HITL learning is to minimise the human costs, whilst maintaining the accuracy of the AI models that result.
This in turn requires the AI model to learn and keep track of the confidence or uncertainty in its predictions. The essential idea is that when the AI system is able to correctly model the uncertainty about its predictions, then only the more uncertain predictions need be checked and corrected, as necessary, by the qualified humans (in the loop); whereas most of its relatively certain (confident) predictions will not need to be checked. The trade off with this approach is that the AI system needs to learn twice as much as before – not only to learn good predictions from the data, but also its level of confidence in each of those predictions.
This approach is analogous to how humans behave in the real world. With vision, for example, anyone who sees a completely new animal type for the first time – say a kangaroo – will most likely be able to recognise it as such (i.e. a new type of animal). Rather than assuming it must be an animal that is already part of their schema (a rabbit?), or worse, simply ignoring it completely (as some machine vision systems have been known to do). Humans recognise their uncertainty and if necessary will seek out advice from someone that might be more knowledgeable.
However, there can be several other benefits to learning this extra information, both for model training and during operation (inference). Instead of models needing to be trained on pre-labelled data sets, they can use semi-supervised, ‘active learning’ techniques. Active learning is a way of ensuring that a model is likely to learn something useful from each of the labelled data points it sees, by identifying only the most ‘instructive’ data points for labelling at each time step. This can allow for far smaller labelled data sets to be used, whilst at the same time benefiting from the much lower cost and higher volume of the remaining unlabelled data. (Pioneers in AutoML systems such as TurinTech are building active learning into their products for exactly this reason.)
Active learning makes it possible for some or all of the data labelling to be done by humans. In fact, in some applications the humans might not even have to do the full labelling, but merely direct the model’s attention to some aspect of the input – for example, by drawing bounding boxes around targeted objects in a training image.
However for machines, accurately quantifying prediction uncertainty is challenging, especially for modern, complex AI systems – despite this having been a goal of the Bayesian machine learning community for quite a while. Thus, a number of startups are starting to emerge that specialise in offering HITL learning as a service. Humanloop for instance, offers a HITL platform to allow users to rapidly annotate data, train and deploy Natural Language Processing (NLP) models.
As well as being potentially much more efficient in the use of humans, HITL learning can also lead to better models, as it facilitates more modern AI methods that can discover better underlying representations of data. Conversely, when the model is being used in production, there can be applications where it makes sense for the model to divert cases that it is currently unsure about (the ‘edge cases’) for human experts to deal with. Of course, ideally this expert input will not be lost and the model can be continuously updated as part of an ‘online learning’ system.
Such HITL online learning makes particular sense when dealing with issues of especial human concern – issues such as fairness, accountability and transparency – or in situations where errors could be costly, such as in medical settings (or at the extreme, in autonomous weapons). HITL can also quickly flag when a model starts to drop in accuracy or fairness (at least in contexts where humans are better judges of these issues) – an all-too-common problem when real world conditions depart from the data sets used during training.
Interestingly, there are some domains where humans do not model their uncertainty well, such as in understanding their own levels of ability. This is famously illustrated by the Dunning Kruger Effect,
a cognitive bias where people with low ability at a task tend to overestimate their ability, and people with high ability at a task, whilst they judge more accurately their own abilities in absolute terms, tend to underestimate their ability compared to others. As the old saying goes, “a little knowledge is a dangerous thing”.
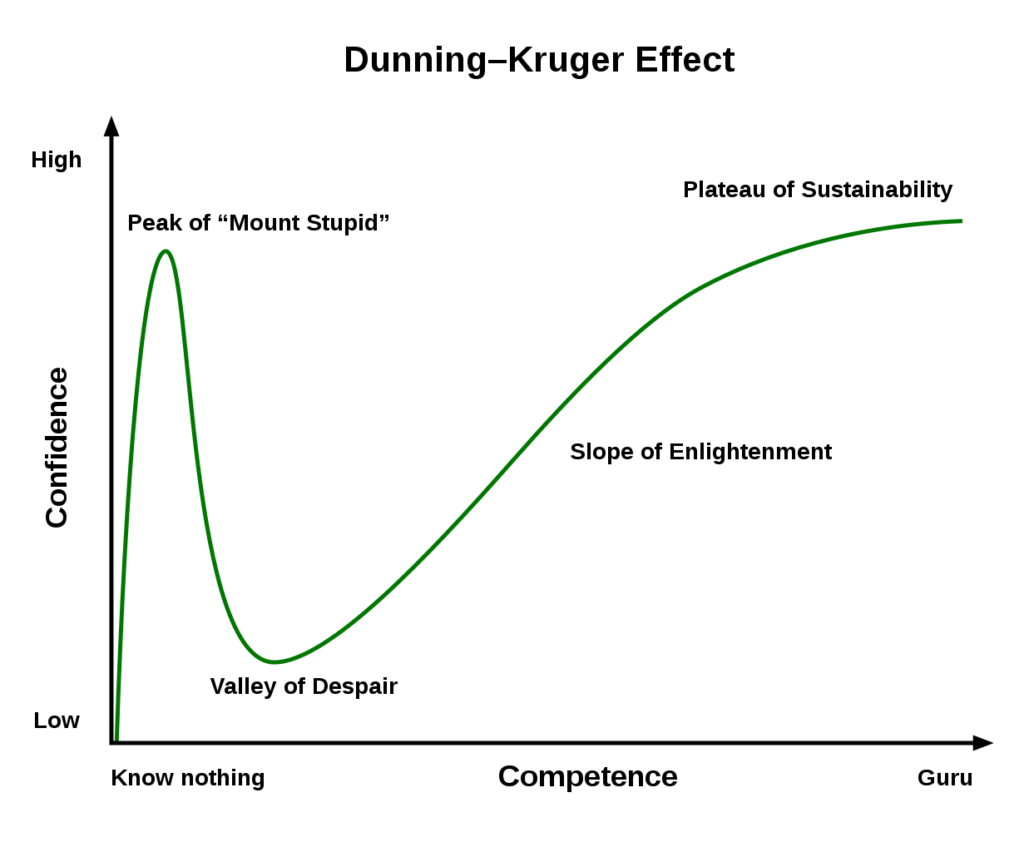
These cognitive biases are further explored in Steven Sloman’s excellent book ‘The Knowledge Illusion‘ which explains why people think they know more than they do – for example they conflate others’ expertise for their own.
The success of HITL learning makes clear that our judgments and decisions will likely improve if only we invest the effort to better calibrate our own confidence in them. It shows we would learn more quickly and with less bias if we made a habit of seeking out different opinions and conflicting data, with which to test and update our mental models of the world.
It seems that both good data science, and good citizenship, require epistemic humility.