
Unpacking autonomous scientific discovery
By Jonno Evans and Kush Desai
It was great to host an event with SoTA on self-driving labs last week. Thanks to the SoTA team for pulling it together and for an amazing turn out!

We’ve been thinking about self-driving labs for a while and have tried to distill our thoughts into something vaguely coherent. But no doubt there are lots of gaps, so please pass on thoughts and feedback. And if you’re building in this space, please reach out to Jonno or Kush!
--
Self-driving labs are having a moment. Nature named them one of 2025’s technologies to watch. Periodic Labs emerged with a $300m seed and Lila Sciences raised $235m to build AI Science Factories. NIST is writing standards. And it is not just a US story: the UK’s Sovereign AI Unit issued an open call for autonomous lab proposals in late 2025, and ARIA has doubled its AI Scientist programme to £6m, funding 12 projects exploring systems that can reason, plan, and execute experiments without continuous human intervention.
It’s clearly a seductive pitch: combine frontier AI with lab robots and you get a recursive engine for scientific discovery. But most of the conversation tends to focus on the AI, while what gets far less attention is the infrastructure underneath, the problem of making labs interoperable, data comparable, and operations reliable enough that autonomy actually works. But we’re getting ahead of ourselves…
What is a self-driving lab?
First, some definitional hygiene. A self-driving lab (SDL) is not “robots plus AI.” We see it as a closed-loop experimental production system: one that can plan, execute, measure, capture provenance, learn, decide the next action, and repeat safely. That framing matters because it positions SDLs as comprehensive experimental infrastructure, not a single piece of kit.
Plenty of labs already have robots. Plenty use machine learning. But closed-loop autonomy, where the system decides what to do next without a human in the loop, is qualitatively different from automating a protocol.
But there’s also an important distinction to draw out here between operations and intelligence.
The operations relate to whether the system can plan, execute, measure, and iterate without a human in the loop. That is an infrastructure problem relating to hardware, orchestration, data and reproducibility. The intelligence is about what the models can actually do with the data the system generates.
Today, AI in the lab is fundamentally an optimisation tool. A closed-loop system generates new data, trains models on that data, and uses those models to search more efficiently through a known space. Each cycle improves the priors. The models get better at predicting which experiments are worth running, which regions of parameter space are most promising, which synthesis routes are most likely to succeed. This is powerful, but the questions being asked are still fundamentally in-distribution i.e. the system is getting faster at finding things within a space that a human has already defined, a set of known unknowns.
The deeper question is whether these systems can eventually search out of distribution. Not just optimising within a parameter space but noticing that the parameter space itself is wrong, or that something unexpected in the data points toward a question nobody thought to ask, a set of unknown unknowns. This is closer to what we actually mean by scientific intuition. Fleming did not optimise his way to penicillin. Röntgen was not running a Bayesian search when he noticed X-rays. The best bench scientists are constantly internalising patterns in their data, developing a feel for anomalies, following threads. Until now, that intuition has not been a scalable resource.
High-throughput autonomous labs have the potential to move towards the latter. When a system is running thousands of experiments and capturing structured data on every outcome, including the failures, it generates raw material for pattern recognition at a scale no human could match. The question is whether the intelligence layer can learn to do something with that material beyond interpolation - can learn to be surprised? If it can, that opens up a genuinely new kind of AI scientist, not a faster optimiser, but a system capable of expanding the frontiers of what we know to look for.
We don’t really know whether it’s possible. What we do know is that the infrastructure has to come first either way. If the models remain in-distribution optimisers, better infrastructure still delivers enormous value: faster cycles, higher reproducibility, lower costs, compounding data advantages. And if a breakthrough in out-of-distribution reasoning does arrive, it will only matter if there is a system underneath that can act on it, one that can reliably execute experiments, capture provenance, and transfer discoveries across labs and into manufacturing.
Whichever way the intelligence bet plays out, the infrastructure bottleneck is the same. What follows is how we think about it.
The experimental infrastructure stack
A useful way to think about the state of SDL development is in levels, loosely analogous to the autonomy levels used in self-driving cars.
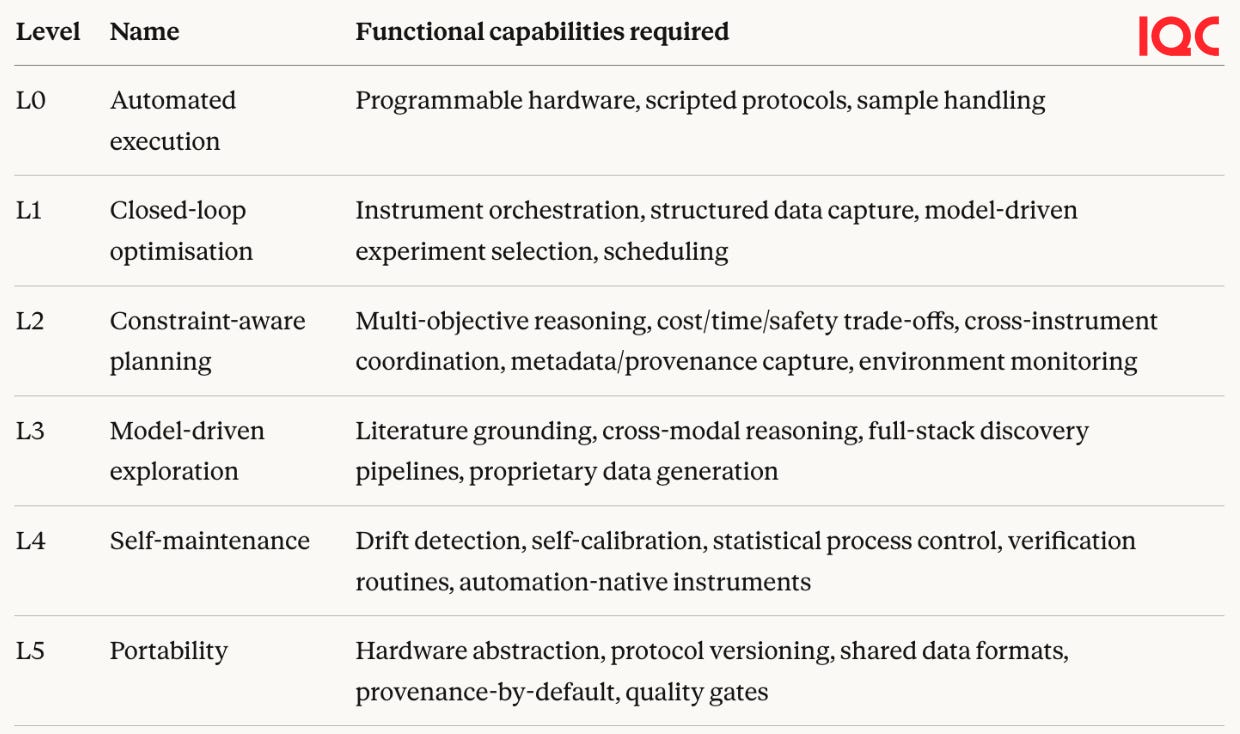
Level 0: Automated execution. Robots run pre-defined scripts. A researcher programmes a liquid handler to pipette samples according to a fixed protocol. The machine does what it’s told, but makes no decisions.
Companies here sell automation hardware that labs deploy on-site. OpenTrons provides affordable, open-source liquid handlers in thousands of academic labs. Chemspeed offers modular robotic workstations for automated synthesis and process R&D. Tecan, Flow Robotics and North Robotics cover liquid handling and sample prep at various scales.
The benefits centre on cost and speed. In a world where a Chinese CRO will develop an antibody against any molecule you name, Western labs are unlikely to compete on labour costs, scale or time. Automated systems that run around the clock with fewer errors are valuable, but a liquid handler that follows a script is still just a productivity tool.
Level 1: Closed-loop optimisation. The system runs an experiment, fits a model, and chooses the next experiment to run. This level is where lab orchestration meets hardware: software that connects instruments, manages scheduling, and plugs in AI-driven experiment planning.
Atinary offers no-code Bayesian optimisation that plugs into existing lab hardware. Biosero and Labric coordinate instruments and manage workflows. Synthace translates experimental designs into automation instructions across devices, with structured data capture built in. The data plane underpinning this includes Benchling (structured records for scientists), TetraScience (instrument data connectors), and Elemental Machines (real-time equipment and environment monitoring). UniteLabs and Scispot are building lab operating systems that tie these pieces together.
The prize here is data quality and integration. Problems like compound formulations or yield optimisations, laborious iterative parameter tuning within known basins, become tractable when the system reasons about what to try next rather than grinding through a grid.
Level 2: Constraint-aware planning. The system reasons about time, cost, safety, uncertainty, and multi-objective trade-offs, not just raw parameter optimisation. This is harder because the optimiser needs to understand the real-world limits of the lab.
Centralised automation platforms operate at this level. Emerald Cloud Lab manages over 200 instrument types under one software layer with full metadata capture. Strateos provides a similar model, with Eli Lilly building a drug discovery facility on their platform. Arctoris and Culture Biosciences offer remote experiments-as-a-service. Intrepid Labs‘ Valiant platform balances manufacturability, cost-of-goods and release kinetics simultaneously, while Molecule One automates retrosynthesis through to robotic execution. Automata builds modular robotic benches with software orchestration, and Medra AI and Zeon Systems are betting on general-purpose robots to bypass bespoke instrument integration entirely.
Scientific research has become irreducibly multimodal. A single materials discovery campaign might generate data in different formats from different instruments across synthesis, diffraction, microscopy and mechanical testing. A single closed loop that optimises one variable is useful, but a closed loop that cannot talk to other loops is inherently limited. The bottleneck is coordination rather than computation. L2 is about combining loops, dealing with multiple parameters simultaneously, and finding optimal conditions within complex chemical or biological space.
Level 3: Model-driven exploration. The system navigates known search spaces more intelligently. It has better priors, feeding in the known literature, prior experiments, and cross-modal reasoning, and uses them to propose which experiments to run next. This is not yet true hypothesis generation in the scientific sense: the system is searching within a space a human has defined. But it starts closer to good answers and gets there faster.
I wrote more about the power of this concept in Activation Energy:
Modern models and workflows start closer to “good” because they have internalised a lot of the structure of the domain.
Companies here bundle lab automation with AI to build full-stack discovery pipelines. Periodic Labs is building autonomous labs for generating new data through physical experimentation. Lila Sciences is constructing “AI Science Factories” where AI designs experiments, robots run them, and results feed back to refine models. Recursion has over 65 petabytes of biological data from its automated platform. Edison Scientific is building AI agents that read literature and design experiments. Chemify has developed a chemistry programming language that runs directly on robotic synthesis hardware.
The promise of L3 is repeatable rather than random exploration. Proprietary data generated at L1 and L2 is what gives L3 models an edge. Foundation models alone only get you so far without novel data to train on.
L0 through L3 describe what the system can do: execute, optimise, plan, explore. Levels 4 and 5 describe what it takes to make all of that work reliably, at scale, across contexts. They are infrastructure maturity levels rather than new autonomous capabilities, which is why they are particularly hard.
Level 4: Self-maintenance. The system detects drift, runs verification experiments, recalibrates, and improves its own processes. This is the natural extension of the previous levels: as you remove humans from the loop, the system must take over the monitoring and repair work that humans usually do. Can an autonomous lab detect that DNA yields have changed because someone switched from fresh to cryopreserved blood samples, identify the root cause, and propose new protocol steps? That is the kind of thing a good lab technician notices and fixes without being asked. Drift detection, statistical process control, reference materials and verification routines are well-understood techniques in manufacturing. The challenge is that nobody has applied them systematically to research labs, because research labs have always had humans as the quality assurance layer.
There is also a hardware dimension. It’s not yet clear whether self-maintenance demands purpose-built instruments or whether sufficiently good orchestration software can abstract away the limitations of existing ones. But there are good reasons to think otherwise. Instruments that require physical intervention to reload, that lose calibration in ways software cannot detect, or that were never designed to expose the data an autonomous planner needs will always cap the system’s autonomy at the level of its least capable device. If that is right, we will need automation-native instruments that embed programmatic control from the ground up.
Level 5: Portability. Workflows and decision policies that transfer across different instruments, sites, and operators. This is a coordination problem that sits on top of everything below it. Real labs are heterogeneous. Instruments from different manufacturers behave differently even when they nominally do the same thing. A solid-state synthesis route that succeeds in one tube furnace may fail in another because ramp profiles and atmospheres differ. A “spin-coat and anneal” for a thin film means different things on different lines.
The technical pieces for portability largely exist e.g. hardware abstraction, protocol versioning, shared data formats. The incentive structures do not. Everyone would benefit from interoperability, but nobody is individually incentivised to build it. Instrument makers profit from lock-in. Labs have no margin to invest in compatibility with systems they don’t control. It is a classic problem of the commons: the value of standardisation accrues to the network, but the cost falls on individual actors who capture almost none of that value.
This is unlikely to be solved by publishing a spec, but rather by embedding standardisation in the system that runs the lab. This might mean hardware abstraction across heterogeneous instruments, protocol versioning and execution, provenance-by-default capturing metadata on every action including failures, and quality gates that enforce consistency. Without this, each SDL will remain bespoke.
Pieces of this exist. Emerald Cloud Lab built centralised management software for over 200 instrument types. Strateos operates a similar model. Benchling provides the data layer. A labOS from the Acceleration Consortium provides workflow management for autonomous materials labs. But none have achieved the full stack at scale. The cloud labs are expensive and geographically concentrated. The orchestration companies sit on top of fragmented hardware they do not control. The instrument makers are adding APIs to legacy products. Every player solves part of the problem but nobody solves the integration.
Without comparability and reproducibility, none of the compounding benefits materialise. Without metadata like calibration states, reagent lots, instrument configurations, and ambient conditions, models infer clean relationships that break on transfer to manufacturing. One example is that negative results (e.g. failed syntheses from materials discovery research) rarely make it into papers, but are precisely what models need.
L4 and L5 create a true network, where systems monitor themselves rather than quietly degrading, and where discoveries in one lab can be reproduced in another. The compounding effect could be enormous. But the commons problem means it’s hard for such a network to emerge organically from the bottom up.
This is strikingly similar to computing before the cloud. In the early 2000s, every company ran its own servers, in its own data centre, with its own configuration. AWS did not win because it invented better servers. It won because it made compute reliable, standard, and composable at scale.
SDLs today are artisanal server farms.
Three paths
So how do we move up the levels? We see three broad paths.
Path A: Coordinated standardisation from the bottom up. Many smaller players, each solving a piece of the stack, connected by shared standards, ontologies, and interfaces. NIST writes the specs. Instrument makers add APIs. Academic consortia like the Acceleration Consortium and initiatives like ARIA’s AI Scientist programme push the research frontier. The UK Sovereign AI Unit’s open call could help by offering national compute infrastructure and public-private partnerships. This is the internet standards model: slow, committee-driven, but eventually robust. There will be lots of Path A. Every well-funded research university and national lab initiative will produce useful work at L1 through L3. But without a forcing function, the commons problem means it is unlikely to deliver L4 or L5 at scale.
Path B: Vertically integrated, closed-source discovery engines. This is the bet that the largest-funded players are making. Periodic Labs, Lila Sciences, and possibly others (e.g. Project Prometheus) are deploying hundreds of millions to build physical lab infrastructure from scratch, co-designed with an AI layer. These are not software companies adding a lab; they are lab companies built around software. Demand is internally led in that they are building infrastructure to run their own experiments and make their own discoveries, not to sell lab services. The infrastructure is the moat; the product is the science that comes out of it. The challenge is whether the discovery engine actually delivers. Can these companies find their miracle material or drug, and then monetise it at sufficient scale to justify the capital invested? Do they license the IP with sufficient royalties to capture value, or do they themselves have to sell into complex global supply chains? Path B solves the standardisation problem by owning the whole stack, but only for one organisation.
Path C: Open, multi-tenant platforms that treat experimentation like compute. Lab time priced as a service, allocated dynamically, governed by service-level agreements. Synthesis, measurement, and characterisation offered not as machines to be booked but as services to be called. Protocols defined in software and executed through version-controlled interfaces. A control plane managing heterogeneous instruments and sites so that multiple locations act as one logical lab. The economics mirror cloud computing: high fixed costs, low marginal costs, improving margins as utilisation rises. A platform at scale could run hundreds of thousands of experiments per year, priced by complexity, with further revenue from data storage, provenance, and optimisation services.
There is no true Path C player today, and the honest question is whether there is enough external demand to justify one. Cloud computing took off because every business needed, and continues to need, a server. Not every company is running science experiments. The addressable market for experiment-as-a-service is narrower and lumpier than the market for compute-as-a-service was.
This is why the most likely route may be B to C. Companies like Periodic and Lila build closed infrastructure to serve their own internal demand, prove the economics, then gradually open the platform to external users as utilisation and capability mature. Internal demand funds the buildout and returns some value in the short-term before external demand funds the scaling. This is, in fact, the better AWS analogy: Amazon built its compute infrastructure to run its own retail business, proved it worked at scale, and only then opened it up as a service. The history of infrastructure suggests that the systems which reach true scale impose standardisation by default rather than by committee. Countries that build this kind of lab infrastructure gain domestic control over critical technology development, faster discovery cycles, and a durable strategic asset that compounds over time.
But which of these paths is most likely to produce genuine scientific breakthroughs, not just faster optimisation within known spaces? That depends on a question the infrastructure alone cannot answer.
Final thoughts
There is a massive amount of energy around SDLs, and the prize could be commensurately large. The right architecture is not yet settled, the paths are multiple, and the companies that get it right will compound advantages that are very difficult to replicate. We are paying close attention. If you are building in this space, we would love to hear from you.
This blog was first published on Techpolitik.



.png)



